A few weeks ago, I was at the annual meeting of the NIH Collaboratory, which is an innovative collection of collaboratory cores, demonstration projects, and NIH Institutes and Centers that is developing new models for implementing and supporting large-scale health services research. A study I am involved with - Primary Palliative Care for Emergency Medicine - is one of the demonstration projects in this collaboratory.
The second day of this meeting included four panels devoted to the design and analysis of embedded pragmatic clinical trials, and focused on the challenges of conducting rigorous research in the real-world context of a health delivery system. The keynote address that started off the day was presented by David Murray of NIH, who talked about the challenges and limitations of cluster randomized trials. (I’ve written before on issues related to clustered randomized trials, including here.)
In particular, Dr. Murray talked a great deal about stepped-wedge designs, which have become a quite popular tool in health services research. (I described stepped-wedge designs here.) A big takeaway from the talk was that we must be cognizant of the underlying assumptions of the models used to estimate treatment effects; being unaware can lead to biased estimates of treatment effects, or more likely, biased estimates of uncertainty.
Intra-cluster correlations
If outcomes of subjects in a study are correlated in any way (e.g. they received care from the same health care provider), we do not learn as much information from each individual study participant as we would in the case where there is no correlation. In a parallel designed cluster randomized trial (where half of the clusters receive an intervention and the other half do not), we expect that the outcomes will be correlated within each cluster, though not across clusters. (This is not true if the clusters are themselves clustered, in which case we would have a 2-level clustered study.) This intra-cluster correlation (ICC) increases sample size requirements and reduces precision/power.
A common way to model correlation explicitly in a cluster randomized trial is to conceive of a random effects model like this:
\[(1) \qquad \qquad Y_{ic} = \mu + \beta_1X_{c} + b_c + e_{ic},\]
where \(Y_{ic}\) is a continuous outcome for subject \(i\) in cluster \(c\), and \(X_c\) is a treatment indicator for cluster \(c\) (either 0 or 1). The underlying structural parameters are \(\mu\), the grand mean, and \(\beta_1\), the treatment effect. The unobserved random effects are, \(b_c \sim N(0, \sigma^2_b)\), the normally distributed group level effect, and \(e_{ic} \sim N(0, \sigma^2_e)\), the normally distributed individual-level effect. (This is often referred to as the “error” term, but that doesn’t adequately describe what is really unmeasured individual variation.)
The correlation between any two subjects \(i\) and \(j\) in the same cluster \(c\) is:
\[ cor(Y_{ic}, Y_{jc}) = \frac{cov(Y_{ic}, Y_{jc})} {\sqrt {var(Y_{ic})var(Y_{jc})}} \]
\(cov(Y_{ic}, Y_{jc})\) can be written in terms of the parameters in the underlying data generating process:
\[ \begin{aligned} cov(Y_{ic}, Y_{jc}) &= cov(\mu + \beta_1X_c + b_c + e_{ic}, \mu + \beta_1X_c + b_c + e_{jc}) \\ &=cov(b_c, b_c) + cov(e_{ic},e_{jc} ) \\ &=\sigma^2_b + 0 \\ &=\sigma^2_b \end{aligned} \]
The terms simplify since the cluster level effects are independent of the individual level effects (and all the fixed effects in the model) and the individual level effects are independent of each other. The within-period intra-cluster co-variance depends only on the between cluster variation.
The total variance of the outcomes \(Y_{ic}\) is:
\[ \begin{aligned} var(Y_{ic}) &= var(\mu + \beta_1X_c + b_c + e_{ic}) \\ &= var(b_c) + var(e_{ic}) \\ &= \sigma^2_b + \sigma^2_e \end{aligned} \]
Substituting all of this into the original equation gives us the intra-cluster correlation for any two subjects in the cluster:
\[ \begin{aligned} cor(Y_{ic}, Y_{jc}) &= \frac{cov(Y_{ic}, Y_{jc})} {\sqrt {var(Y_{ic})var(Y_{jc})}} \\ \\ ICC &= \frac{\sigma^2_b}{\sigma^2_b + \sigma^2_e} \end{aligned} \]
So, the correlation between any two subjects in a cluster increases as the variation between clusters increases.
Cluster randomization when time matters
Moving beyond the parallel design to the stepped-wedge design, time starts to play a very important role. It is important to ensure that we do not confound treatment and time effects; we have to be careful that we do not attribute the general changes over time to the intervention. This is accomplished by introducing a time trend into the model. (Actually, it seems more common to include a time-specific effect so that each time period has its own effect. However, for simulation purposes, I will will assume a linear trend.)
In the stepped-wedge design, we are essentially estimating within-cluster treatment effects by comparing the cluster with itself pre- and post-intervention. To estimate sample size and precision (or power), it is no longer sufficient to consider a single ICC, because there are now multiple ICC’s - the within-period ICC and the between-period ICC’s. The within-period ICC is what we defined in the parallel design (since we effectively treated all observations as occurring in the same period.) Now we also need to consider the expected correlation of two individuals in the same cluster in different time periods.
If we do not properly account for within-period ICC and the between-period ICC’s in either the planning or analysis stages, we run the risk of generating biased estimates.
My primary aim is to describe possible data generating processes for the stepped wedge design and what implications they have for both the within-period and between-period ICC’s. I will generate data to confirm that observed ICC’s match up well with the theoretical expectations. This week I will consider the simplest model, one that is frequently used but whose assumptions may not be realistic in many applications. In a follow-up post, I will consider more flexible data generating processes.
Constant ICC’s over time
Here is probably the simplest model that can be conceived for a process underlying the stepped-wedge design:
\[ (2) \qquad \qquad Y_{ict} = \mu + \beta_0t + \beta_1X_{ct} + b_c + e_{ict} \]
As before, the unobserved random effects are \(b_c \sim N(0, \sigma^2_b)\) and \(e_{ict} \sim N(0, \sigma^2_e)\). The key differences between this model compared to the parallel design is the time trend and time-dependent treatment indicator. The time trend accounts for the fact that the outcome may change over time regardless of the intervention. And since the cluster will be in both the control and intervention states we need to have an time-dependent intervention indicator. (This model is a slight variation on the Hussey and Hughes model, which includes a time-specific effect \(\beta_t\) rather than a linear time trend. This paper by Kasza et al describes this stepped-wedge model, and several others, in much greater detail.)
The within-period ICC from this is model is:
\[ \begin{aligned} cor(Y_{ict}, Y_{jct}) &= cor(\mu + \beta_0t + \beta_1X_{ct} + b_c + e_{ict}, \ \mu + \beta_0t + \beta_1X_{ct} + b_c + e_{jct}) \\ \\ ICC_{tt}&= \frac{\sigma^2_b}{\sigma^2_b + \sigma^2_e} \end{aligned} \]
I have omitted the intermediary steps, but the logic is the same as in the parallel design case. The within-period ICC under this model is also the same as the ICC in the parallel design.
More importantly, in this case the between-period ICC turns out to be the same as the within-period ICC. For the between-period ICC, we are estimating the expected correlation between any two subjects \(i\) and \(j\) in cluster \(c\), one in time period \(t\) and the other in time period \(t^\prime\) \((t \ne t^\prime)\):
\[ \begin{aligned} cor(Y_{ict}, Y_{jct^\prime}) &= cor(\mu + \beta_0t + \beta_1X_{ct} + b_c + e_{ict}, \ \mu + \beta_0t^\prime + \beta_1X_{ct^\prime} + b_c + e_{jct^\prime}) \\ \\ ICC_{tt^\prime}&= \frac{\sigma^2_b}{\sigma^2_b + \sigma^2_e} \end{aligned} \]
Under this seemingly reasonable (and popular) model, we are making a big assumption that the within-period ICC and between-period ICC’s are equal and constant throughout the study. This may or may not be reasonable - but it is important to acknowledge the assumption and to make sure we justify that choice.
Generating data to simulate a stepped-wedge design
I’ve generated data from a stepped-wedge design before on this blog, but will repeat the details here. For the data definitions, we define the variance of the cluster-specific effects, the cluster sizes, and the outcome model.
defc <- defData(varname = "ceffect", formula = 0, variance = 0.15,
dist = "normal", id = "cluster")
defc <- defData(defc, "m", formula = 10, dist = "nonrandom")
defa <- defDataAdd(varname = "Y",
formula = "0 + 0.10 * period + 1 * rx + ceffect",
variance = 2, dist = "normal")The data generation follows this sequence: cluster data, temporal data, stepped-wedge treatment assignment, and individual (within cluster) data:
dc <- genData(100, defc)
dp <- addPeriods(dc, 7, "cluster")
dp <- trtStepWedge(dp, "cluster", nWaves = 4, lenWaves = 1, startPer = 2)
dd <- genCluster(dp, cLevelVar = "timeID", "m", "id")
dd <- addColumns(defa, dd)
dd## cluster period ceffect m timeID startTrt rx id Y
## 1: 1 0 -0.073 10 1 2 0 1 -2.12
## 2: 1 0 -0.073 10 1 2 0 2 -1.79
## 3: 1 0 -0.073 10 1 2 0 3 1.53
## 4: 1 0 -0.073 10 1 2 0 4 -1.44
## 5: 1 0 -0.073 10 1 2 0 5 2.25
## ---
## 6996: 100 6 0.414 10 700 5 1 6996 1.28
## 6997: 100 6 0.414 10 700 5 1 6997 0.30
## 6998: 100 6 0.414 10 700 5 1 6998 0.94
## 6999: 100 6 0.414 10 700 5 1 6999 1.43
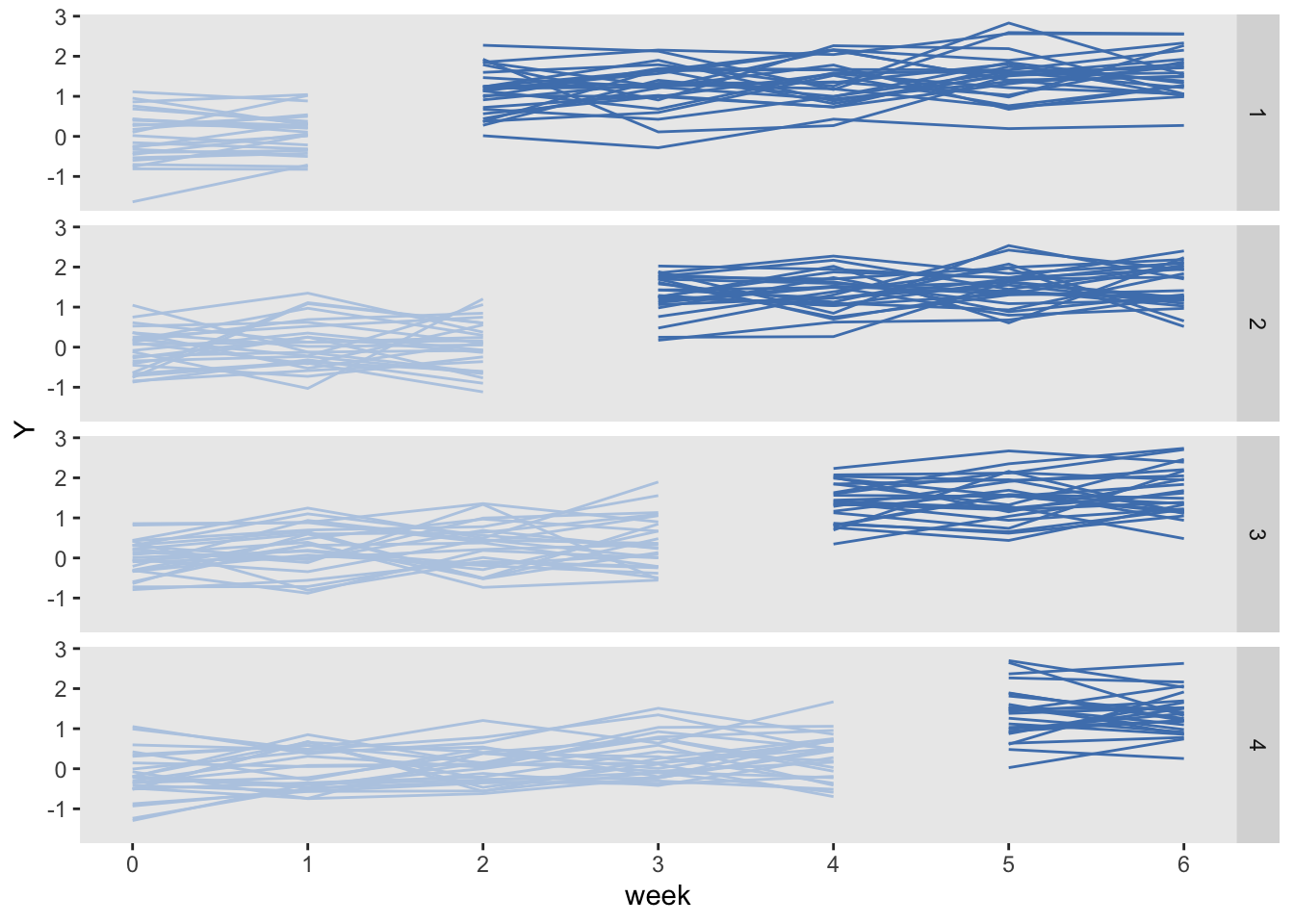
## 7000: 100 6 0.414 10 700 5 1 7000 0.58It is always useful (and important) to visualize the data (regardless of whether they are simulated or real). This is the summarized cluster-level data. The clusters are grouped together in waves defined by starting point. In this case, there are 25 clusters per wave. The light blue represents pre-intervention periods, and the dark blue represents intervention periods.
Estimating the between-period within-cluster correlation
I want to estimate the observed between-period within cluster correlation without imposing any pre-conceived structure. In particular, I want to see if the data generated by the process defined in equation (2) above does indeed lead to constant within- and between-period ICC’s. In a future post, I will estimate the ICC using a model, but for now, I’d prefer to estimate the ICC’s directly from the data.
A 1982 paper by Bernard Rosner provides a non-parametric estimate of the between-period ICC. He gives this set of equations to find the correlation coefficient \(\rho_{tt^\prime}\) for two time periods \(t\) and \(t^\prime\). In the equations, \(m_{ct}\) represents the cluster size for cluster \(c\) in time period \(t\), and \(K\) represents the number of clusters:
\[ \rho_{tt^\prime} = \frac{\sum_{c=1}^K \sum_{i=1}^{m_{ct}} \sum_{j=1}^{m_{ct^\prime}} (Y_{ict}-\mu_t)(Y_{jct^\prime}-\mu_{t^\prime})} {\left[ \left ( \sum_{c=1}^K m_{ct^\prime} \sum_{i=1}^{m_{ct}} (Y_{ict}-\mu_t)^2 \right ) \left ( \sum_{c=1}^K m_{ct} \sum_{j=1}^{m_{ct^\prime}} (Y_{jct^\prime}-\mu_{t^\prime})^2 \right )\right] ^ \frac {1}{2}} \]
\[ \mu_t = \frac{\sum_{c=1}^K m_{ct} m_{ct^\prime} \mu_{ct}}{\sum_{c=1}^K m_{ct} m_{ct^\prime}} \ \ , \ \ \mu_{t^\prime} = \frac{\sum_{c=1}^K m_{ct} m_{ct^\prime} \mu_{ct^\prime}}{\sum_{c=1}^K m_{ct} m_{ct^\prime}} \]
\[ \mu_{ct} = \frac{\sum_{i=1}^{m_{ct}} Y_{ict}}{m_{ct}} \ \ , \ \ \mu_{ct^\prime} = \frac{\sum_{j=1}^{m_{ct^\prime}} Y_{jct^\prime}}{m_{ct^\prime}} \]
I’ve implemented the algorithm in R, and the code is included in the addendum. One issue that came up is that as the intervention is phased in over time, the treatment effect is present for each at different times. The algorithm breaks down as a result. However, the between-period ICC can be calculated for each wave, and then we can average across the four waves.
The within-period ICC is estimated using a linear mixed effects model applied to each period separately, so that we estimate period-specific within-period ICC’s. The expected (constant) ICC is \(0.07 = \left(\frac{0.15}{0.15 + 2}\right)\).
The function iccs (shown below in the addendum) returns both the estimated within- and between-cluster ICC’s for a single data set. Here is the within-period ICC for the first period (actually period 0) and the between-period ICC’s using period 0:
set.seed(47463)
iccs(dd, byWave = T)[,c(22, 0:6)]## wp0 bp01 bp02 bp03 bp04 bp05 bp06
## 1: 0.041 0.068 0.073 0.08 0.067 0.054 0.053ICC estimates are quite variable and we can’t tell anything about the distribution from any single data set. Generating multiple replications lets us see if the estimates are close, on average, to our assumption of constant ICC’s. Here is a function to generate a single data set:
genDD <- function(defc, defa, nclust, nperiods, waves, len, start) {
dc <- genData(nclust, defc)
dp <- addPeriods(dc, nperiods, "cluster")
dp <- trtStepWedge(dp, "cluster", nWaves = waves,
lenWaves = len, startPer = start)
dd <- genCluster(dp, cLevelVar = "timeID", "m", "id")
dd <- addColumns(defa, dd)
return(dd[])
}And here is a function to estimate 200 sets of ICC’s for 200 data sets:
icc <- mclapply(1:200,
function(x) iccs(genDD(defc, defa, 100, 7, 4, 1, 2), byWave = T),
mc.cores = 4
)
observed <- sapply(rbindlist(icc), function(x) mean(x))Averages of all the within- and between-period ICC’s were in fact quite close to the “true” value of 0.07 based on a relatively small number of replications. The plot shows the observed averages along side the expected value (shown in gray) for each of the periods generated in the data. There is little variation across both the within- and between-period ICC’s.

I’ll give you a little time to absorb this. Next time, I will consider alternative data generating processes where the the ICC’s are not necessarily constant.
References:
Kasza, J., K. Hemming, R. Hooper, J. N. S. Matthews, and A. B. Forbes. “Impact of non-uniform correlation structure on sample size and power in multiple-period cluster randomised trials.” Statistical methods in medical research (2017): 0962280217734981.
Rosner, Bernard. “On the estimation and testing of inter-class correlations: the general case of multiple replicates for each variable.” American journal of epidemiology 116, no. 4 (1982): 722-730.
Addendum: R code for simulations
library(lme4)
library(parallel)
Covar <- function(dx, clust, period1, period2, x_0, x_1) {
v0 <- dx[ctemp == clust & period == period1, Y - x_0]
v1 <- dx[ctemp == clust & period == period2, Y - x_1]
sum(v0 %*% t(v1))
}
calcBP <- function(dx, period1, period2) {
# dx <- copy(d2)
# create cluster numbers starting from 1
tt <- dx[, .N, keyby = cluster]
nclust <- nrow(tt)
dx[, ctemp := rep(1:nclust, times = tt$N)]
dx <- dx[period %in% c(period1, period2)]
## Grand means
dg <- dx[, .(m=.N, mu = mean(Y)), keyby = .(ctemp, period)]
dg <- dcast(dg, formula = ctemp ~ period, value.var = c("m","mu"))
setnames(dg, c("ctemp", "m_0", "m_1", "mu_0", "mu_1"))
x_0 <- dg[, sum(m_0 * m_1 * mu_0)/sum(m_0 * m_1)]
x_1 <- dg[, sum(m_0 * m_1 * mu_1)/sum(m_0 * m_1)]
## Variance (denominator)
dss_0 <- dx[period == period1, .(ss_0 = sum((Y - x_0)^2)),
keyby = ctemp]
dss_0[, m_1 := dg[, m_1]]
v_0 <- dss_0[, sum(m_1 * ss_0)]
dss_1 <- dx[period == period2, .(ss_1 = sum((Y - x_1)^2)),
keyby = ctemp]
dss_1[, m_0 := dg[, m_0]]
v_1 <- dss_1[, sum(m_0 * ss_1)]
## Covariance
v0v1 <- sapply(1:nclust,
function(x) Covar(dx, x, period1, period2, x_0, x_1))
bp.icc <- sum(v0v1)/sqrt(v_0 * v_1)
bp.icc
}
btwnPerICC <- function(dd, period1, period2, byWave = FALSE) {
if (byWave) {
waves <- dd[, unique(startTrt)]
bpICCs <- sapply(waves, function(x)
calcBP(dd[startTrt==x], period1, period2))
return(mean(bpICCs))
} else {
calcBP(dd, period1, period2)
}
}
withinPerICC <- function(dx) {
lmerfit <- lmer(Y~rx + (1|cluster), data = dx)
vars <- as.data.table(VarCorr(lmerfit))[, vcov]
vars[1]/sum(vars)
}
genPairs <- function(n) {
x <- combn(x = c(1:n-1), 2)
lapply(seq_len(ncol(x)), function(i) x[,i])
}
iccs <- function(dd, byWave = FALSE) {
nperiods <- dd[, length(unique(period))]
bperiods <- genPairs(nperiods)
names <-
unlist(lapply(bperiods, function(x) paste0("bp", x[1], x[2])))
bp.icc <- sapply(bperiods,
function(x) btwnPerICC(dd, x[1], x[2], byWave))
system(paste("echo ."))
bdd.per <- lapply(1:nperiods - 1, function(x) dd[period == x])
wp.icc <- lapply(bdd.per,
function(x) withinPerICC(x))
wp.icc <- unlist(wp.icc)
nameswp <- sapply(1:nperiods - 1, function(x) paste0("wp", x))
do <- data.table(t(c(bp.icc, wp.icc)))
setnames(do, c(names, nameswp))
return(do[])
}